Table of Contents
Triggering a NHB Note Eviction on Node grac2
$ ifconfig eth1 down
You can increase CSSD log level to 3 to trace each each heartbeat message: ( do this on all involved notes )
# $GRID_HOME/bin/crsctl set log css CSSD:3
Set CSSD Module: CSSD Log Level: 3
# $GRID_HOME/bin/crsctl get log css CSSD
Get CSSD Module: CSSD Log Level: 3
Check the current CSS timeout values
# $GRID_HOME/bin/crsctl get css misscount
CRS-4678: Successful get misscount 30 for Cluster Synchronization Services.
Review CRS Logfile
- $GRID_HOME/log/grac1/cssd/ocssd.log
- $GRID_HOME/log/grac2/cssd/ocssd.log
- $GRID_HOME/log/grac1/alertgrac1.log
- $GRID_HOME/log/grac2/alertgrac2.log
- alert_GRACE21.log
- alert_GRACE22.log
Check ocssd.log on both RAC Nodes
Node grac2
$ cat $GRID_HOME/log/grac2/cssd/ocssd.log | egrep -i 'Removal|evict|30000|network HB' 2013-08-01 15:15:10.500: [ CSSD][380536576]clssnmHBInfo: css timestmp 1375362910 500 slgtime 13000084 DTO 27750 (index=1) biggest misstime 110 NTO 28390 2013-08-02 09:52:43.287: [ CSSD][382113536]clssnmPollingThread: node grac1 (1) at 50% heartbeat fatal, removal in 14.960 seconds 2013-08-02 09:52:51.294: [ CSSD][382113536]clssnmPollingThread: node grac1 (1) at 75% heartbeat fatal, removal in 6.950 seconds 2013-08-02 09:52:55.296: [ CSSD][382113536]clssnmPollingThread: node grac1 (1) at 90% heartbeat fatal, removal in 2.950 seconds, seedhbimpd 1 2013-08-02 09:52:55.296: [ CSSD][382113536]clssnmPollingThread: node grac1 (1) at 90% heartbeat fatal, removal in 2.950 seconds, seedhbimpd 1 2013-08-02 09:52:55.297: [ CSSD][388421376]clssnmvDHBValidateNCopy: node 1, grac1, has a disk HB, but no network HB, DHB has rcfg 269544449, wrtcnt, 547793, LATS 2298 6504, lastSeqNo 547787, uniqueness 1375343446, timestamp 1375429975/22995684 2013-08-02 09:52:55.298: [ CSSD][389998336](:CSSNM00005:)clssnmvDiskKillCheck: Aborting, evicted by node grac1, number 1, sync 269544449, stamp 22996044 2013-08-02 09:52:55.299: [ CSSD][399468288](:CSSNM00005:)clssnmvDiskKillCheck: Aborting, evicted by node grac1, number 1, sync 269544449, stamp 22996044 2013-08-02 09:52:55.301: [ CSSD][394729216](:CSSNM00005:)clssnmvDiskKillCheck: Aborting, evicted by node grac1, number 1, sync 269544449, stamp 22996044 2013-08-02 09:52:56.297: [ CSSD][388421376]clssnmvDHBValidateNCopy: node 1, grac1, has a disk HB, but no network HB, DHB has rcfg 269544449, wrtcnt, 547799, LATS 2298 7504, lastSeqNo 547793, uniqueness 1375343446, timestamp 1375429976/22996684 2013-08-02 09:52:57.300: [ CSSD][388421376]clssnmvDHBValidateNCopy: node 1, grac1, has a disk HB, but no network HB, DHB has rcfg 269544449, wrtcnt, 547805, LATS 2298 8504, lastSeqNo 547799, uniqueness 1375343446, timestamp 1375429977/22997694 2013-08-02 09:53:23.461: [ CSSD][3078596352]clssnmSetParamsFromConfig: remote SIOT 27000, local SIOT 27000, LIOT 200000, misstime 30000, reboottime 3000, impending mi sstime 15000, voting file reopen delay 4000 GRID_HOME/log/grac2/alertgrac2.log [cssd(2869)]CRS-1611:Network communication with node grac1 (1) missing for 75% of timeout interval. Removal of this node from cluster in 6.950 seconds 2013-08-02 09:52:55.296 [cssd(2869)]CRS-1610:Network communication with node grac1 (1) missing for 90% of timeout interval. Removal of this node from cluster in 2.950 seconds 2013-08-02 09:52:55.298 [cssd(2869)]CRS-1608:This node was evicted by node 1, grac1; details at (:CSSNM00005:) in /u01/app/11203/grid/log/grac2/cssd/ocssd.log. 2013-08-02 09:52:55.298 [cssd(2869)]CRS-1656:The CSS daemon is terminating due to a fatal error; Details at (:CSSSC00012:) in /u01/app/11203/grid/log/grac2/cssd/ocssd.log 2013-08-02 09:52:55.298 [cssd(2869)]CRS-1652:Starting clean up of CRSD resources. 2013-08-02 09:52:55.298 [cssd(2869)]CRS-1608:This node was evicted by node 1, grac1; details at (:CSSNM00005:) in /u01/app/11203/grid/log/grac2/cssd/ocssd.log. 2013-08-02 09:52:55.301 [cssd(2869)]CRS-1608:This node was evicted by node 1, grac1; details at (:CSSNM00005:) in /u01/app/11203/grid/log/grac2/cssd/ocssd.log. 2013-08-02 09:52:56.573 [/u01/app/11203/grid/bin/oraagent.bin(3255)]CRS-5016:Process "/u01/app/11203/grid/opmn/bin/onsctli" spawned by agent "/u01/app/11203/grid/bin/oraagent.bin" for action "check" failed: details at "(:CLSN00010:)" in "/u01/app/11203/grid/log/grac2/agent/crsd/oraagent_grid/oraagent_grid.log"
Node grac1
$ cat $GRID_HOME/log/grac2/cssd/ocssd.log | egrep 'Removal|evict|30000' 2013-08-01 15:15:10.500: [ CSSD][380536576]clssnmHBInfo: css timestmp 1375362910 500 slgtime 13000084 DTO 27750 (index=1) biggest misstime 110 NTO 28390 2013-08-02 09:52:55.298: [ CSSD][389998336](:CSSNM00005:)clssnmvDiskKillCheck: Aborting, evicted by node grac1, number 1, sync 269544449, stamp 22996044 2013-08-02 09:52:55.299: [ CSSD][399468288](:CSSNM00005:)clssnmvDiskKillCheck: Aborting, evicted by node grac1, number 1, sync 269544449, stamp 22996044 2013-08-02 09:52:55.301: [ CSSD][394729216](:CSSNM00005:)clssnmvDiskKillCheck: Aborting, evicted by node grac1, number 1, sync 269544449, stamp 22996044 2013-08-02 09:53:23.461: [ CSSD][3078596352]clssnmSetParamsFromConfig: remote SIOT 27000, local SIOT 27000, LIOT 200000, misstime 30000, reboottime 3000, impending misstime 15000, voting file reopen delay 4000 cat $GRID_HOME/log/grac1/alertgrac1.log cssd(2933)]CRS-1612:Network communication with node grac2 (2) missing for 50% of timeout interval. Removal of this node from cluster in 14.630 seconds 2013-08-02 09:52:49.504 [cssd(2933)]CRS-1611:Network communication with node grac2 (2) missing for 75% of timeout interval. Removal of this node from cluster in 6.630 seconds 2013-08-02 09:52:53.504 [cssd(2933)]CRS-1610:Network communication with node grac2 (2) missing for 90% of timeout interval. Removal of this node from cluster in 2.630 seconds 2013-08-02 09:52:56.141 [cssd(2933)]CRS-1607:Node grac2 is being evicted in cluster incarnation 269544449; details at (:CSSNM00007:) in /u01/app/11203/grid/log/grac1/cssd/ocssd.log. 2013-08-02 09:52:59.148 [cssd(2933)]CRS-1625:Node grac2, number 2, was manually shut down 2013-08-02 09:52:59.160 [cssd(2933)]CRS-1601:CSSD Reconfiguration complete. Active nodes are grac1 . 2013-08-02 09:52:59.176 [crsd(3205)]CRS-5504:Node down event reported for node 'grac2'. 2013-08-02 09:53:08.632 [crsd(3205)]CRS-2773:Server 'grac2' has been removed from pool 'Generic'. 2013-08-02 09:53:08.632 [crsd(3205)]CRS-2773:Server 'grac2' has been removed from pool 'ora.GRACE2'. --> Here we know that grac2 was evicted by grac1. Verify this by reading related alert.log files
Review alert.logs
alert_GRACE21.log ( ASM termination ) Note grac2: ASM instance gets terminated SKGXP: ospid 3625: network interface with IP address 169.254.86.205 no longer running (check cable) SKGXP: ospid 3625: network interface with IP address 169.254.86.205 is DOWN Fri Aug 02 09:52:57 2013 NOTE: ASMB terminating Errors in file /u01/app/oracle/diag/rdbms/grace2/GRACE22/trace/GRACE22_asmb_3649.trc: ORA-15064: communication failure with ASM instance ORA-03113: end-of-file on communication channel Process ID: Session ID: 31 Serial number: 7 Errors in file /u01/app/oracle/diag/rdbms/grace2/GRACE22/trace/GRACE22_asmb_3649.trc: ORA-15064: communication failure with ASM instance ORA-03113: end-of-file on communication channel Process ID: Session ID: 31 Serial number: 7 ASMB (ospid: 3649): terminating the instance due to error 15064 Instance terminated by ASMB, pid = 3649 alert_GRACE22.log ( Instance recovery and resource reallocation Node grac1 Global resources are recovered and Instance Recovery takes place: ri Aug 02 09:53:00 2013 Reconfiguration started (old inc 4, new inc 6) List of instances: 1 (myinst: 1) Global Resource Directory frozen * dead instance detected - domain 0 invalid = TRUE Communication channels reestablished Master broadcasted resource hash value bitmaps Non-local Process blocks cleaned out Fri Aug 02 09:53:00 2013 LMS 0: 0 GCS shadows cancelled, 0 closed, 0 Xw survived Set master node info Submitted all remote-enqueue requests Dwn-cvts replayed, VALBLKs dubious All grantable enqueues granted Post SMON to start 1st pass IR Submitted all GCS remote-cache requests Post SMON to start 1st pass IR Fix write in gcs resources Reconfiguration complete Fri Aug 02 09:53:00 2013 Instance recovery: looking for dead threads Beginning instance recovery of 1 threads Started redo scan Completed redo scan read 6 KB redo, 4 data blocks need recovery Started redo application at Thread 2: logseq 5, block 26368 Recovery of Online Redo Log: Thread 2 Group 3 Seq 5 Reading mem 0 Mem# 0: +DATA/grace2/onlinelog/group_3.266.822058427 Completed redo application of 0.00MB Completed instance recovery at Thread 2: logseq 5, block 26380, scn 1541989 4 data blocks read, 4 data blocks written, 6 redo k-bytes read Thread 2 advanced to log sequence 6 (thread recovery) Fri Aug 02 09:53:02 2013 minact-scn: Master considers inst:2 dead
Lets have a short look on Cluster Health monitor files ( CHM)
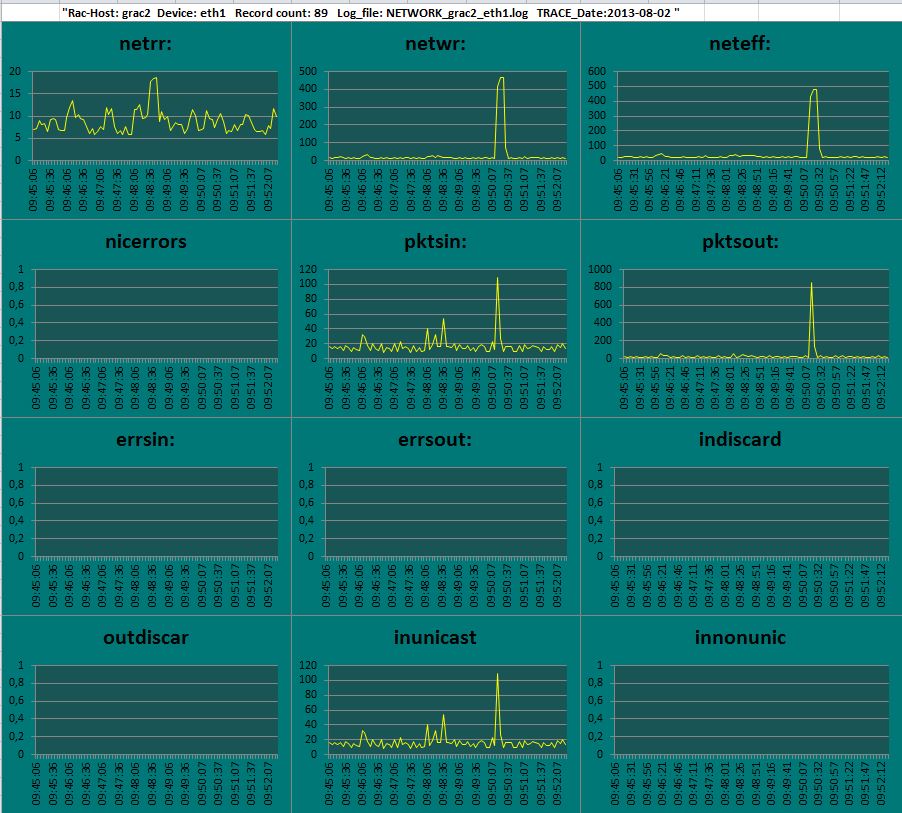

Summary
- Node grac2 stops reporting after 9:53 as we have stopped the Cluster interconnect interface eht1 on grac2
- Note grac1 shows that all Network activies drops to 0 after 9:53 ( see netrr, netwr, neteff )
What’s up it’s me, I am also visiting this web site daily, this web page is genuinely
good and the people are genuinely sharing nice thoughts.
Hi peer,
Can we increase the time interval network heartbeat.
Regards
Here is a good descripion how to do it :
https://sort.veritas.com/public/documents/sfha/6.0.1/linux/productguides/html/sfrac_install/ch23s05.htm
But note this high value should be used only if you use a vendor clusterware.